Table des matières
Bonjour à tous,
Aujourd’hui, nous allons traiter de différents sujets, d’où le titre de cet article. J’ai en effet pas mal divagué, que ce soit sur le serveur ou pour d’autres projets. De ce fait, je ne peux pas écrire un article sur un sujet spécifique, ce qui me lance sur ce nouveau type d’articles.
Moteurs de recherches
Je vous disais récemment que j’étais revenu sur Google car searx ne fonctionnait plus toujours très bien. La version 0.16.0 de ce dernier est sortie récemment, et j’ai mis à jour mes instances pour l’occasion. Après cela, je suis revenu dessus et je l’ai remis par défaut sur les navigateurs de mes PC pro et perso mais également mon téléphone.
Un autre point qui m’a motivé à revenir sur searx est le fait que Google n’affiche plus les URL dans ses résultats de recherche. Dans cet exemple, la version de la documentation est masquée:
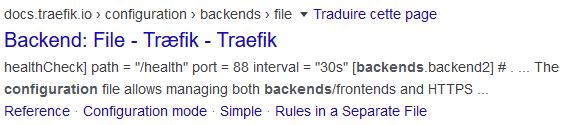
Avec un script Greasemonkey (il vient d’ici), voici ce que l’on obtient:
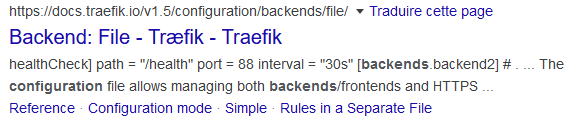
Le problème, c’est que la version 1.5 de Traefik n’est pas celle qui m’intéresse, je veux la 2.x. Désormais, Google ne m’affiche donc plus par défaut cette information …
Le script a tout de même un défaut lorsque les URL sont trop longues, le bouton Traduire la page se superpose avec le titre:

Mise à jour et configuration de searx
La mise à jour de searx s’est faite relativement simplement. Ensuite, dans le fichier de configuration, j’ai passé en revue les moteurs un par un pour désactiver ceux qui posaient problèmes (comme Google qui bloque les recherches) ou ceux qui étaient trop lents.
Sur mon instance searx.pofilo.fr, j’ai donc:
- Désactivé les moteurs deviantart et duckduckgo_images ainsi que tous les moteurs google car ce dernier bloque les requêtes automatiques.
- Activé les moteurs duckduckgo et qwant.
- Configuré mon instance pour mettre à disposition un result_proxy. Cela permet d’avoir le bouton proxifié dans la liste des résultats des recherches pour que ce soit mon serveur qui charge la page pour vous.
- activé l’option image_proxy pour que toutes les images s’affichant dans la section images soit chargée via morty. Les images affichées dans l’encart Wikipédia dans l’onglet principal ne sont d’ailleurs pas traitée par morty, je regarderai ce point quand j’aurai un peu de temps :)

Je possède également une autre instance sur le même serveur. Elle est configurée pour mes besoins personnels, à savoir très peu de modifications sur le code mais pas mal de changements sur les moteurs utilisés.
D’un point de vue configuration, j’ai également mis à jour les règles CSP (Content Security Policy) qui est (selon Wikipédia) un mécanisme de sécurité standardisé permettant de restreindre l’origine de contenu (Javascript notamment) dans une page web pour certains sites autorisés. Cela permet de mieux se prémunir contre des attaques d’injection de code.
La règle que j’ai donc modifiée dans ma configuration d’apache est donc la suivante (en grande partie inspirée de celle présente dans l’image docker de searx):
Header always set Content-Security-Policy "upgrade-insecure-requests;default-src 'none';script-src 'self';style-src 'self' 'unsafe-inline';form-action 'self';font-src 'self';frame-ancestors 'self';base-uri 'self';connect-src 'self';img-src 'self' data: https://*.tile.openstreetmap.org https://morty.pofilo.fr;frame-src https://www.youtube-nocookie.com https://player.vimeo.com https://www.dailymotion.com https://www.deezer.com https://www.mixcloud.com https://w.soundcloud.com https://embed.spotify.com"
Liste des instances de searx
Ceux qui ne peuvent/désirent/savent pas héberger une instance de searx pouvaient autrefois trouver une liste d’instances sur le Wiki de searx. Cette liste est maintenant accessible sur searx.space et est modifiable depuis git sur le dépôt searx-instances pour tous via des Pull requests.
Les mesures que l’on retrouve sur searx.space sont traitées via searx-stats2. Les mesures de temps sont relatives pour l’instant au seul serveur faisant les mesures, donc ces valeurs ne sont pertinentes que pour l’Europe de façon générale.
Autrement, je vous conseille d’utiliser des instances possédant la dernière version et si possible avec A+ sur la note TLS donnée par CryptCheck ainsi que A++ sur la note CSP donnée par l’Observatory by mozilla. Je vous conseille enfin d’utiliser une instance avec le code Vanilla, ce qui garantie que les fichiers sont les mêmes que ceux sous le dépôt officiel de searx (l’administrateur de l’instance peut toujours vous espionner via les logs si ceux-ci ne sont pas désactivés, mais vous ne devriez pas avoir de code malicieux lors de vos recherches).
Reste à faire
Voilà ce qui me reste à faire sur searx:
- Passer sous Python 3, je suis malheureusement encore avec UWGSI et Python 2 …
- Activer l’IPv6 sur mon serveur de façon générale (battez-moi si vous pensez que ça devrait être déjà le cas, je gère ce serveur sur mon temps de loisir et je n’ai pas le temps de tout faire malheureusement …).
- Faire tourner un petit script pour mettre à jour les informations sur les moteurs de mon instance sur l’onglet Engines de searx.space.
- Mettre en place filtron, un autre logiciel par le créateur de searx pour protéger searx contre les robots en instaurant des règles sur les requêtes effectuées. La configuration présente dans l’image docker officielle de searx est présente ici, je pense que je vais simplement la reprendre dans mon cas.
- Enfin, je possède les droits de merger sur searx ainsi que searx-instances, alors je vais essayer de participer un peu plus :)
Docker
Je possède de plus en plus de logiciels sur mon serveur et mon Raspberry Pi mais je n’utilise pas encore Docker (ou équivalent) et je commence à y songer sérieusement.
Après, ce n’est pas magique. Le Raspberry étant sous ARM, pas mal d’images (comme MariaDB notammment) ne sont pas officiellement disponibles .. Là où je pensais que Docker permettait de s’abstraire de l’environnement dans lequel il tourne, eh bien pas du tout …
J’ai également commencé à vouloir utiliser des outils récents tels que Traefik en tant que reverse-proxy mais sa documentation n’est vraiment pas terrible, et je n’arrive pas encore à le configurer correctement (de façon à avoir A+ sur SSL-Labs et CryptCheck). Pour l’instant, là ou SSL-Labs me retourne la note de B mais reconnait tout de même le certificat, un simple wget ou curl me retourne:
ERROR: The certificate of ‘xx.xx.xx’ is not trusted.
ERROR: The certificate of ‘xx.xx.xx’ doesn't have a known issuer.
Si des gens savent comment exploiter les fichiers .pem d’un certificat wildcard généré (en dehors de Docker) dans Traefik v2.x (il s’agit en l’occurrence d’un certificat généré par Let’s Encrypt mais peu importe normalement).
Après, un logiciel tel que Traefik n’a pas encore la maturité d’un Apache ou nginx. Quel reverse-proxy me conseillez-vous d’utiliser sous Docker ?
Wallabag et plop-reader
J’utilise FreshRSS comme agrégateur de Flux RSS. Étant abonné au Monde et à NextInpact mais en suivant également de nombreux autres flux, je me retrouve à devoir trier beaucoup d’articles différents. C’est là que Wallabag entre en jeu. Quand un article m’intéresse (via le titre), je l’envoie sur Wallabag pour une lecture ultérieure sans distraction (bien que je lise encore certains articles directement depuis FreshRSS forcément). Comme je me base sur le titre des articles, je bannis tout ce qui est titre putaclic.
Je possède une liseuse Touch HD Plus de Vivlio (anciennement Tea) et il existe une application nommée plop-reader qui permet de récupérer les articles d’un compte Wallabag sur la liseuse. Pour des gros articles (notamment ceux du Monde), c’est vraiment intéressant et agréable à utiliser. J’ai cependant repéré un problème de timezone dans l’application, il faut que je trouve quelque temps pour tenter de le corriger (et en profiter pour augmenter la taille des boutons dans l’application).
Conclusion
Un retour sur searx, beaucoup de temps sur Docker et notamment Traefik et des lectures agréables via Wallabag, voilà qui nous dit au mois prochain pour un nouvel article !