Table des matières
Bonjour à tous,
Aujourd’hui, je vais vous faire un petit retour d’expérience après avoir mis en place du monitoring sur mon infra.
Tout d’abord, j’ai depuis longtemps l’excellent Uptime Kuma pour surveiller la disponibilité de mes serveurs et services. Concrètement, mon instance de Uptime Kuma va vérifier régulièrement si mes services répondent correctement (monitoring actif). Mais il y a aussi l’inverse, à la fin de mes scripts de sauvegarde, je fais un appel à Uptime Kuma (monitoring passif).
Le tout me permet d’être averti si mes sauvegardes ou des services (Nextcloud, Vaultwarden, etc…) ne fonctionnent plus.
Mise en place du monitoring
Surveiller que tout soit fonctionnel, c’est bien. Mais s’assurer en plus que les machines ne soient pas surchargées, c’est mieux.
Mon infra est relativement simple:
- un serveur principal sur lequel tourne la majorité de mes services (dans des containers)
- un Raspberry Pi 4 à la maison pour faire tourner Home Assistant notamment
Je n’ai donc pas besoin d’un monitoring complexe mais de quelque chose de simple et efficace. C’est pour ça que j’ai installé Beszel.
Je vous laisse voir la documentation, Beszel s’installe très facilement et est très léger en ressources. Il y a un hub (serveur) qui centralise les informations remontées par les agents. J’ai donc un hub sur le serveur principal et 2 agents (un sur le serveur principal et l’autre sur le Raspberry Pi).
L’intérêt du monitoring est multiple. On peut être alerté si on dépasse des seuils (consommation CPU, RAM, espace disque, etc…). Mais on peut aussi visualiser un historique clair de la consommation de ces ressources dans le temps.
Après quelques jours, on regarde ce que ça donne
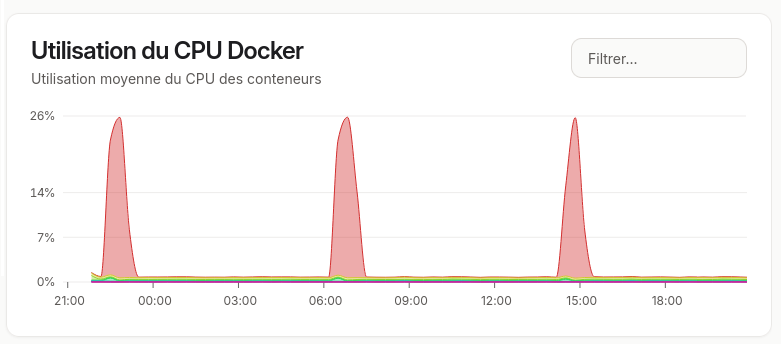
Sur la capture pour le Raspberry Pi, on peut voir des pics liés à un container.
Il s’agit du container home-assistant-db-backup qui est responsable de sauvegarder la base de données de Home Assistant.
Le code source de ce container est du code maison dont voilà le code source.
Le but est simplement de faire un mariadb-dump de la base de données de façon régulière.
J’avais abstrait ça dans un container par simplicité: 0 dépendance sur le système, facilité de migration (le déploiement est dans le même fichier que la base de données elle-même), j’ai pas vraiment besoin de m’en soucier.
L’analyse
À l’époque, j’ai créé cette image Docker pour sauvegarder la base de données de Nextcloud sur mon serveur principal (beaucoup plus puissant qu’un Raspberry Pi).
Par souci d’espace disque (et d’absence de problèmes de CPU), j’avais ajouté une option pour compresser le fichier .sql généré.
Si on regarde bien, j’avais même utilisé le mode de compression extrême de xz (via l’option XZ_OPT=-e9).
Or franchement, c’est totalement overkill.
Voici un mini benchmark pour montrer à quel point ce niveau de compression n’a pas de sens ici.
Le fichier .sql généré par mariadb-backup pèse 229 Mo dans mon cas.
Je vais compresser ce fichier via différents algorithmes et niveaux de compression, à la fois sur mon PC (processeur assez performant 11th Gen Intel(R) Core(TM) i9-11900K @ 3.50GHz) et sur le Raspberry Pi (processeur bien plus modeste ARM Cortex-A72 Quad-core 1,5 GHz).
| Algorithme | Niveau de compression | Commande | Taille finale (Mo) | Durée (PC) | Durée (RPI) |
|---|---|---|---|---|---|
| XZ | 9 | XZ_OPT=-e9 tar -Jcf | 24 | 4m7s | 42m48s |
| XZ | 6 (valeur par défaut) | tar -Jcf | 25 | 13s | 3m1s |
| GZIP | 9 | tar –use-compress-program=‘gzip -9’ -cf | 34 | 22s | 1m8s |
| GZIP | 6 (valeur par défaut) | tar -czf | 35 | 3s | 16s |
| GZIP | 6 avec option rsyncable | tar -c bdd.sql | gzip –rsyncable > bdd.sql.tar.gz | 36 | 3s | 16s |
Donc depuis des années, la sauvegarde de ma base de données prends presque 45 minutes (et ce 3 fois par jour !! …).
Déjà rien qu’avec le niveau de compression par défaut, on “perd” 1 Mo (sur le tar généré) mais on gagne presque 40 minutes … Ensuite, il y a un compromis à choisir entre XZ et GZIP. Ce dernier est 12 fois plus rapide et ne rajoute “que” 10 Mo (ce qui représente 40% du poids du tar initial tout de même).
J’ai ensuite découvert l’option --rsyncable de GZIP: --rsyncable make rsync-friendly archive.
Cela crée en fait des sortes de checkpoints dans le tar final (d’où la taille légèrement plus importante) de sorte que rsync (ou d’autres logiciels) puisse travailler par chunk: si on ne rajoute qu’une ligne dans la base de données, ça ne va modifier qu’un seul chunk dans le tar final et les outils de synchronisations seront donc plus efficaces.
Pour rendre cette option plus efficace encore, j’ai également rajouté l’option --order-by-primary à la commande mariadb-dump.
Elle permet de trier les tables par clés primaires, histoire d’avoir un dump déterministe et donc potentiellement un maximum de chunks identiques dans le tar final.
Sur mon Raspberry Pi, le dump de ma base de Home Assistant prends 23 secondes avec ou sans l’option.
Au final, ce dump de ma base de données va être historisé avec restic (et BorgBackup, mais je suis en train de le remplacer par restic justement). Or restic (borg aussi, mais je vais rester sur restic pour le reste de l’article) va compresser le fichier dans sa snapshot. Mais compresser un fichier compresser, ce n’est pas efficace du tout.
J’ai donc fait des tests avec restic et le dump de ma base de données de Nextcloud (plus gros que celui de Home Assistant, celui-ci pèse 746 Mo). J’ai créé un dépôt restic vierge pour chaque test, et à chaque sauvegarde, j’ai rajouté un fichier (jusqu’à un total de 4 fichiers).
| Type | Taille d’un fichier tar/sql (Mo) | Taille total des 4 fichiers (Mo) | Taille finale du dépot restic (avec les 4 fichiers) (Mo) |
|---|---|---|---|
| Compression XZ-9 | 91 | 364 | 269 |
| Compression GZIP-6 rsyncable | 158 | 632 | 204 |
| Pas de compression | 746 | 2984 | 172 |
Finalement, on le voit très bien.
Sauvegarder des fichiers très compressés n’est pas efficace, tous les chunks sont entièrement différents d’un fichier à l’autre.
Avec l’option --rsyncable, c’est déjà plus efficace.
Et enfin, les .sql pas du tout compressés prennent bien plus de place sur disque mais la déduplication finale sur les sauvegardes est bien plus efficace.
Cela dit, un dump .sql est très compressable en général, ça joue aussi beaucoup sur les chiffres finaux.
Conclusion
Tout est donc question des besoins de chacun. De mon côté, je pars sur l’option sans compression manuelle, je la délègue à restic. Mes sauvegardes prendront donc moins de place, le CPU de mon Raspberry Pi pourra se la couler douce (pas négligeable vu les chaleurs en ce moment) et les courbes de mon monitoring seront beaucoup plus lisses.